Yet another logging post!
There are already many articles about logging in SAP Cloud Integration (aka CPI), so why another one? The reason is obvious:
SAP Cloud Integration does not provide an out-of-the-box logging framework that is both easy to use for developers, and suitable for running enterprise-grade solutions.
Why logging?
While logging is a common and fundamental capability in many programming languages and frameworks, unfortunately it is glaringly missing in SAP Cloud Integration. Since the early days of the platform, there have been many different takes on how to overcome this limitation. Most approaches that use the platform’s internal capabilities tend to revolve around creating MPL attachments using scripts.
Logging is not only limited to storing of the payload body, but also includes providing insight into the state of a message at a certain point during processing of the integration flow or at a certain point of a script. The lack of this capability in CPI results in the following:
- Limited visibility into what happens to a message as it goes through the different steps of an integration flow.
- Inability to toggle between different levels of logging to determine what is logged depending on different scenarios or environment, e.g. certain logs are generated only in non-production environments.
- Coupled with another missing CPI capability, debugging of integration flows, it becomes challenging when developing complex integration scenarios.
While tracing does provide some much needed insight into message processing during runtime, the drawbacks are the short duration it is active, and its resource-intensive nature.
In this post, I will share a handy tip to handle logging in SAP Cloud Integration, drawing from my experience of migrating from SAP Cloud Integration to MuleSoft, combined with an approach that I have successfully used in many CPI implementations.
Enter the Logger
Firstly, as logging is a common functionality that is required in many different steps and/or integration flows, it is beneficial to consolidate the often-used logic. My go-to approach is to create a Groovy class using the modularising CPI Groovy scripts using POGO technique.
The source code below shows a Groovy class named Logger, which has the following key parts:
- Methods info, warn, error that log messages at different log levels – inspired by common Java logging frameworks like Apache Log4j 2.
- Method debug which logs messages when the log level of the integration flow is set to Debug or Trace.
- Overloaded methods saveEntriesInAttachment that create MPL attachments containing messages that are logged.
package src.main.resources.script
import com.sap.gateway.ip.core.customdev.util.Message
class Logger {
final List entries
final String logLevel
final Object messageLog
final Object mpl
static Logger newLogger(Message message, Object messageLogFactory) {
return new Logger(message, messageLogFactory)
}
private Logger() {}
private Logger(Message message, Object messageLogFactory) {
this.entries = []
def mplConfig = message.getProperty('SAP_MessageProcessingLogConfiguration')
this.logLevel = (mplConfig?.getLogLevel() ?: 'INFO') as String
this.messageLog = messageLogFactory?.getMessageLog(message)
this.mpl = message.getProperty('SAP_MessageProcessingLog')
}
void info(String entry) {
this.entries.add("[INFO] " + entry)
}
void warn(String entry) {
this.entries.add("[WARNING] " + entry)
}
void error(String entry) {
this.entries.add("[ERROR] " + entry)
}
void debug(String entry) {
if (this.logLevel == 'DEBUG' || this.logLevel == 'TRACE') {
this.entries.add("[DEBUG] " + entry)
}
}
void saveEntriesInAttachment() {
Set mplKeys = this.mpl.getContainedKeys()
def stepId = this.mpl.get(mplKeys.find { it.getName() == 'StepId' })
saveEntriesInAttachment(stepId)
}
void saveEntriesInAttachment(String attachmentName) {
if (this.messageLog) {
if (this.entries.size()) {
StringBuilder sb = new StringBuilder()
this.entries.each { sb << it + "\r\n" }
this.messageLog.addAttachmentAsString(attachmentName, sb.toString(), 'text/plain')
}
}
}
}Use cases
Now that we have the common functionality in place, we can focus on a couple of use cases that may come in handy. Note that I have deliberately skipped the use case of logging the payload body, since it is a common one that is already widely covered.
1 – Log message content at integration flow level
An instance of a message during runtime execution on CPI consists not only of the main payload body, but also headers and properties. Quite often, processing logic depends not only on the content of the payload body, but also values that are in the headers and/or properties. Therefore, having visibility into the content of the message covering payload body, headers and properties is quite handy when developing or debugging an integration flow.
Inspired by the Logger step available in MuleSoft, the following Groovy script (LogMessage.groovy) is an attempt to provide a similar functionality in CPI. While its MuleSoft counterpart logs the Mule event by default (excluding the actual payload body), this CPI variant logs the payload body, headers and properties along with their corresponding type.
Another difference is that the entries are only logged when the log level is set to Debug. The reason is to limit the creation of MPL attachments only when it is required. Additionally, Debug is active for 24 hours once set, which provides a significantly bigger window than Trace which is only for 10 minutes.
By placing this Groovy script step at key points of an integration flow, valuable insight about the processing of a message becomes available. Such steps can be built in to the design on an integration flow, and do not need to be removed upon completion of the development. This makes it useful not only during the initial development phase, but also provides the capability to troubleshoot issues in the production environment later on.
import com.sap.gateway.ip.core.customdev.util.Message
import src.main.resources.script.Logger
Message processData(Message message) {
Logger logger = Logger.newLogger(message, messageLogFactory)
logger.debug("----- Getting message headers -----")
message.getHeaders().each { String key, Object value ->
if (value instanceof InputStream) {
def reader = message.getHeader(key, Reader)
logger.debug("${key}|${value.getClass().getName()}|${reader.getText()}")
} else {
logger.debug("${key}|${value.getClass().getName()}|${value}")
}
}
logger.debug("----- Getting message properties -----")
message.getProperties().each { String key, Object value ->
if (value instanceof InputStream) {
logger.debug("${key}|${value.getClass().getName()}|{{Value for InputStream skipped}}")
} else {
logger.debug("${key}|${value.getClass().getName()}|${value}")
}
}
logger.debug("----- Getting message body -----")
logger.debug("Body object type = ${message.getBody().getClass().getName()}")
def reader = message.getBody(Reader)
if (reader) {
logger.debug("Body value = ${reader.getText()}")
} else {
logger.debug("Body value = ${message.getBody()}")
}
logger.saveEntriesInAttachment()
return message
}Example
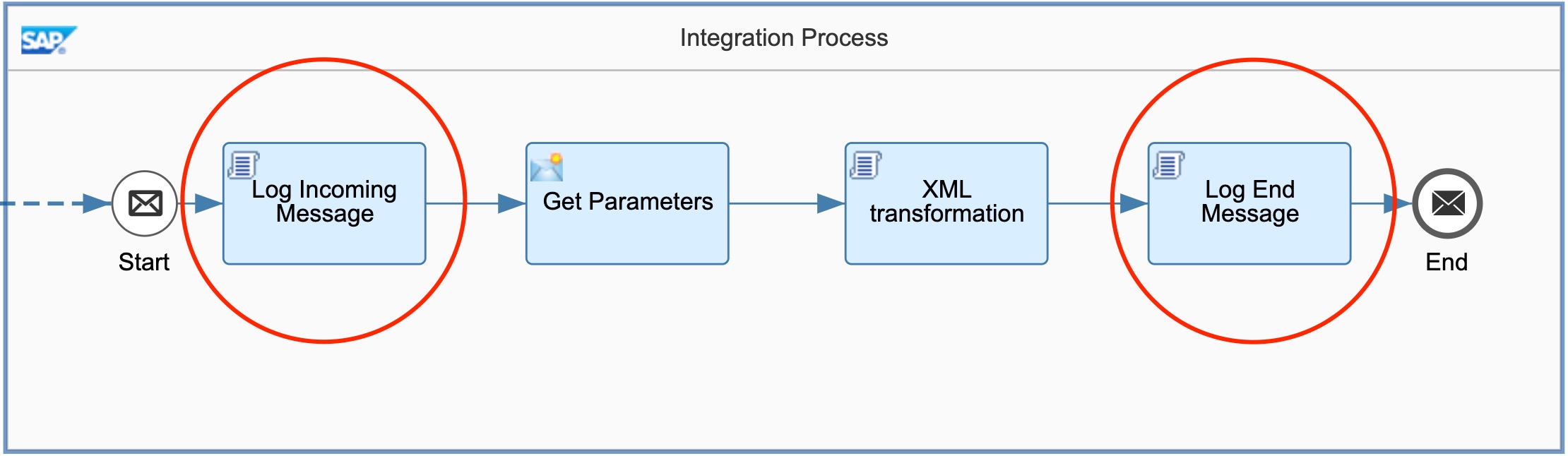
Using the example integration flow with an XML-to-XML transformation from the Developing Groovy Scripts for SAP Cloud Platform Integration E-Bite, additional logging steps are added at the beginning and end of the integration flow. Both the Groovy class (Logger.groovy), and Groovy script (LogMessage.groovy) are uploaded as resources of the integration flow.
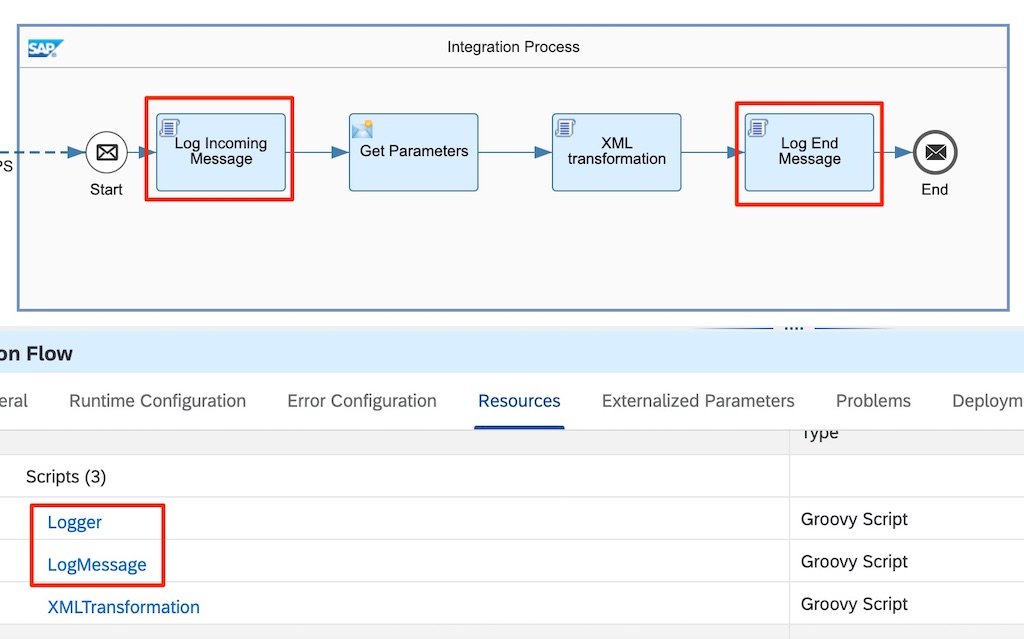
When a message is executed with the log level of the integration flow set to Debug, the following attachments are created. Note that the script automatically derives the name of the attachment from the technical ID of the step.

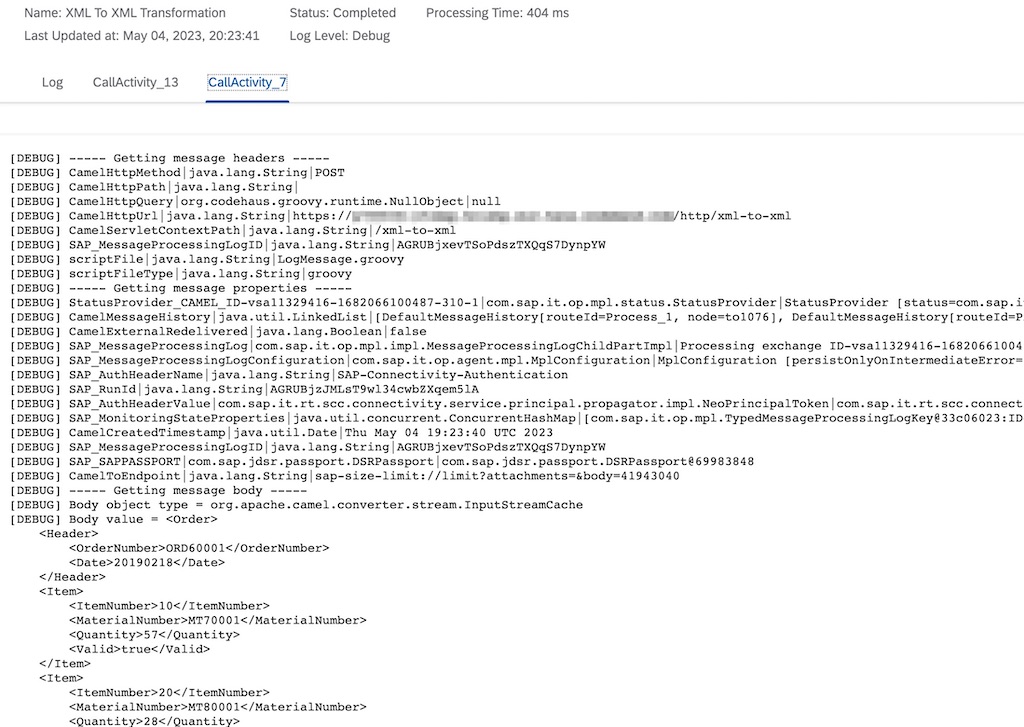
Diving into the content of the attachments, the payload body, headers and properties are now available for inspection. Notice that the corresponding types of the body/header/property are also stated. When developing more complex scenarios, knowledge of types can become important and may make the difference between a well-crafted solution or one that encounters a NoTypeConversionAvailableException: No type converter available to convert from type error.
2 – Log data at script processing level
Another area where logging comes in handy is within the processing of a (Groovy) script. While it is possible and recommended to unit test Groovy scripts in a local IDE first, sometimes there are differences compared to when it is being executed on a CPI tenant. Therefore, generating logs out of Groovy script processing can provide better insight into what happens during execution on a tenant.
With the common logic already encapsulated in the above Logger class, it becomes easy to incorporate logging into any Groovy script. Just create an instance of Logger and call the required logging methods wherever necessary to pass in the required message.
Example
Continuing from the above example, following is the source code of the Groovy script used in the transformation step. The highlighted lines are the statements added for logging purposes. Note that this uses the info and warn methods which will generate log entries irrespective of the log level.
import com.sap.gateway.ip.core.customdev.util.Message
import groovy.xml.MarkupBuilder
import src.main.resources.script.Logger
import java.time.LocalDate
import java.time.format.DateTimeFormatter
def Message processData(Message message) {
Reader reader = message.getBody(Reader)
def Order = new XmlSlurper().parse(reader)
Writer writer = new StringWriter()
def indentPrinter = new IndentPrinter(writer, ' ')
def builder = new MarkupBuilder(indentPrinter)
def docType = message.getProperty('DocType')
// Log processing details
Logger logger = Logger.newLogger(message, messageLogFactory)
logger.info("Document Type = ${docType}")
logger.info("Number of items before filtering = ${Order.Item.size()}")
def items = Order.Item.findAll { it.Valid.text() == 'true' }
logger.info("Number of items after filtering = ${items.size()}")
if (!items.size()) {
logger.warn('No items found!')
}
builder.PurchaseOrder {
'Header' {
'ID' Order.Header.OrderNumber
'DocumentDate' LocalDate.parse(Order.Header.Date.text(),
DateTimeFormatter.ofPattern('yyyyMMdd'))
.format(DateTimeFormatter.ofPattern('yyyy-MM-dd'))
if (!items.size())
'DocumentType' docType
}
items.each { item ->
'Item' {
'ItemNumber' item.ItemNumber.text().padLeft(3, '0')
'ProductCode' item.MaterialNumber
'Quantity' item.Quantity
}
}
}
message.setBody(writer.toString())
logger.saveEntriesInAttachment('Transformation Logs')
return message
}When a message is executed on this integration flow, an attachment named Transformation Logs will be created. The name of the attachment is passed in from line 47 of the source code above.
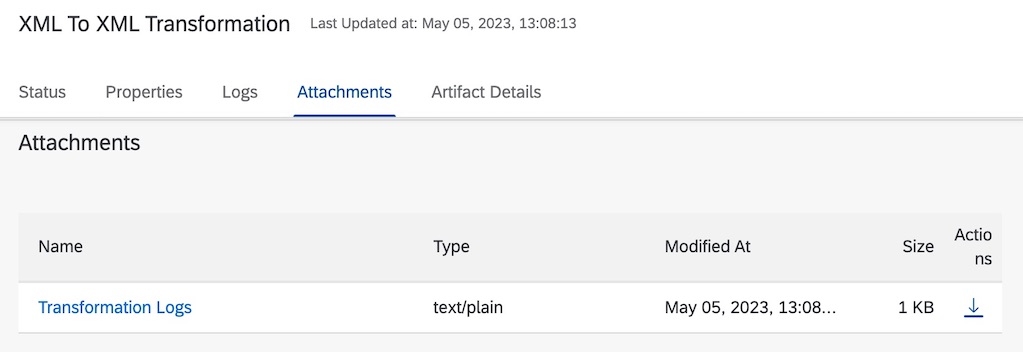
Upon inspection of the attachment, it provides further insight into what happened during the execution of the Groovy script.

Conclusion
Despite the limitation of the platform, the approach described above can significantly improve the quality of the integration flows developed. While the examples used are simplified in order to illustrate the approach in an easy-to-digest manner, it can be scaled and modified for scenarios with higher complexity. For example, the source codes can be modified according to specific needs, i.e. when to log, what to log and what level to log at.
Although it may be possible that logging may not be as crucial for the run-of-the-mill scenarios, for more complex scenarios, it can very well make the difference between a robust enterprise-grade solution versus a buggy and error-prone one.
Comments
Feel free to provide your comment, feedback and/or opinion here.
