Introduction
Recently, I had the opportunity to work on a proof-of-concept development which involves migrating from SAP Cloud Integration to MuleSoft Anypoint Platform. It was an interesting task since both platforms are Leaders in the latest Gartner Magic Quadrant for Integration Platform as a Service report (published in January 2023), so it was a chance to review the technical capabilities using a realistic scenario.
The scenario selected for the proof-of-concept is representative of what is becoming the norm for cloud native integrations – where multiple HTTP/API calls are involved, coupled with application logic and customised error handling. Additionally, this particular integration required further capabilities such as parallel processing, and various payload transformations (filtering, sorting, aggregating, etc).
In this post, I will look into the different aspects that I found noteworthy whilst working on migrating and reimplementing the integration on MuleSoft Anypoint Platform.
From APIs to integrations
MuleSoft is well known for its API-led approach to integration development. Part of this methodology involves creation of an API specification as one of the first steps of the development process, prior to implementing the logic of the integration.
With this outside-in approach to development, the API Specification is first modelled in RAML or OpenAPI format. Using Anypoint Design Center, the modelling can be easily done with the support of an intuitive UI that provides features such as design-time recommendation & autocompletion, interactive API documentation and autosave.
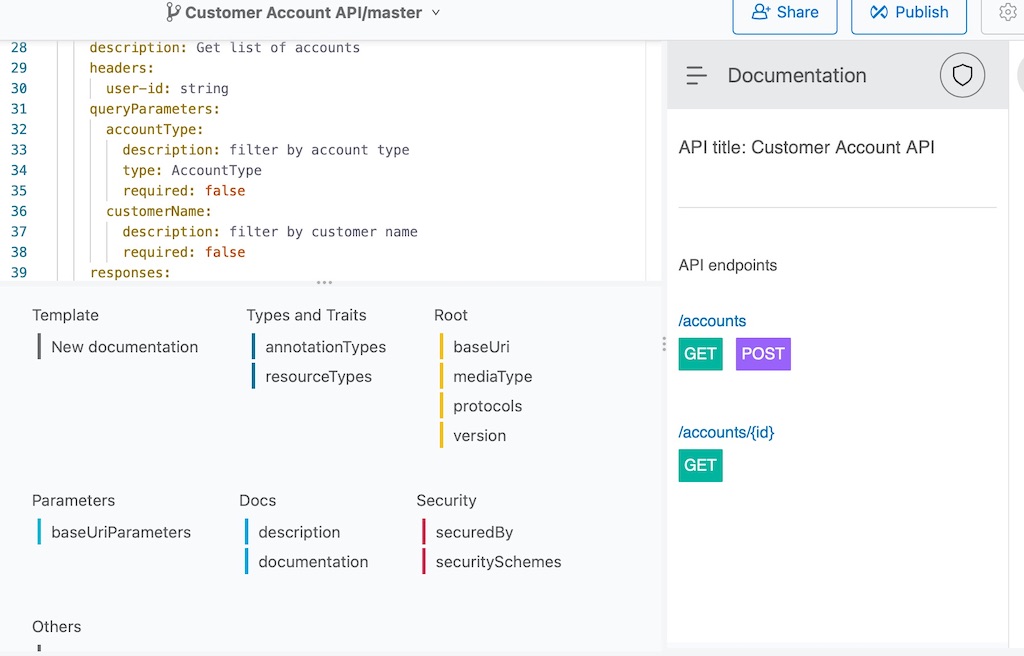
Subsequently, after the API Specification has been completed, a Mule Project is created to implement the logic required for the API. Creation of the Mule Project is done using Anypoint Studio. The IDE provides an option to use APIkit to automatically generate the scaffolding for the flow based on each pair of unique endpoint and method. This generates a structured flow with the necessary listeners and placeholder logic that can be enhanced further with the required logic.
The following example shows a RAML-based specification with a GET method for the /customer endpoint.
/customer:
is: [client-id-required]
get:
description: Get list of customer
queryParameters:
accountType: string
country: string
responses:
200:
body:
application/json:
type: array
items: Customer
examples:
output: !include examples/CustomersExample.ramlAPIkit automatically generates the following flows for the Mule Project – the third flow providing a placeholder for further logic enhancement.
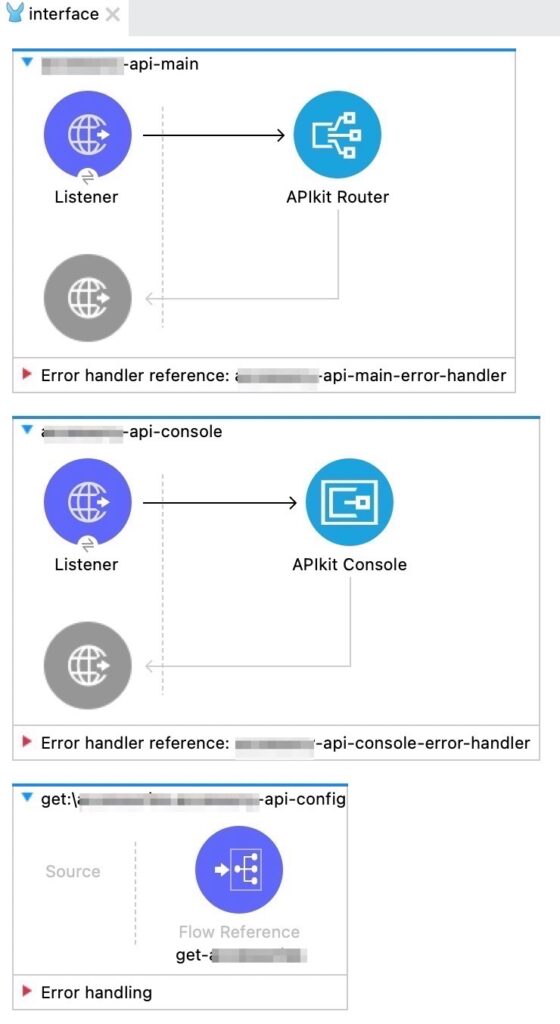
Another benefit of using APIkit is that during runtime, it automatically validates HTTP request calls based on the API specification. For example, if one of the mandatory query parameters (e.g. accountType) is missing, an appropriate HTTP 400 error will be thrown. This is a nice feature as there is no extra work required to handle such basic error handling scenarios.
Overall, the flow of development from modelling the API Specification to implementing the Mule Project is very smooth. In contrast, SAP Integration Suite currently lacks a smooth transition and interoperability when moving between SAP API Management and SAP Cloud Integration.
Layout and XML
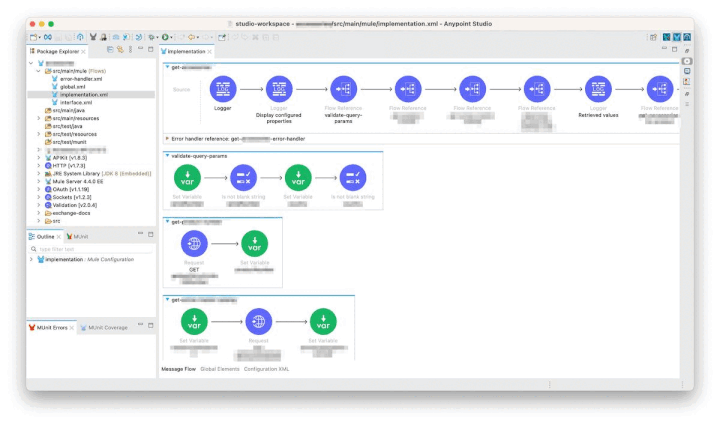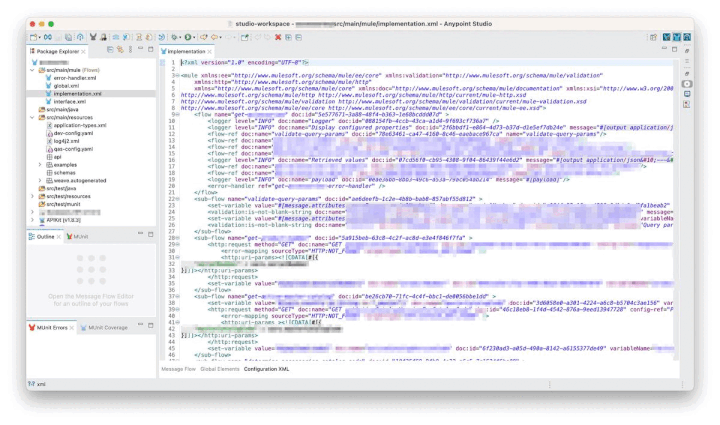
Development of the integration logic in the Mule Project is quite similar to SAP Cloud Integration. It offers a flexible modelling framework not too different from the Apache Camel-based framework used in SAP Cloud Integration.
I particularly liked the layout which is well organised, whereby steps are neatly placed from left to right, and flows from top to bottom. There is no need to resize boxes or move steps around when adding new steps, this is done neatly in an automatic fashion.
Integrations are created as Mule Configuration Files, and they can be switched between the graphical view and the XML representation. Editing the configuration in XML can occasionally be useful and easier, for example when duplicating multiple steps or moving logic from one configuration file to another.
As the configurations are file-based, this makes it easy to manage with Git. Version changes can be reviewed by comparing the differences between the XML code of the files.
Palette
As mentioned above, its flexible modelling means it is possible to include a variety of steps to construct the integration logic. These steps are provided in the Mule Palette. They mostly conform to Enterprise Integration Patterns and are not too different from what is available in SAP Cloud Integration.
SAP Cloud Integration has a Looping Process step, which is noticeably missing from the Mule Palette. This is similar to a while loop in programming. However, it is possible to implement such requirement using a recursive flow reference call.
The palette steps are organised in groups called Modules. Adding a Module is easy via the UI, and in the background it just adds a new dependency into the Maven POM file of the Mule Project.
Working in local IDE
I am a big proponent of performing development tasks on a local development environment.
Anypoint Studio is an Eclipse-based IDE that enables developers to fully develop and test the integration locally prior to deploying it on the cloud. The benefits of a local development environment are:
- Improved productivity by being able to test the integration prior to deployment
- Perform step-by-step debug of the steps in the flow including actual calls to external systems. This is significantly different from the following features in SAP Cloud Integration
- Tracing – it is only possible to view the message content after execution, with no option of setting breakpoints and also limited to the first 10 minutes of an execution
- Simulation – step-by-step debug is not possible, and actual calls to external systems are not supported
- Perform on-the-fly evaluation of DataWeave expressions (more on this below) – this allows developers to construct DataWeave code using actual data
Since switching over to IntelliJ IDEA for Java & Groovy developments, I have preferred it over the look and feel of Eclipse. Therefore using Anypoint Studio felt a bit outdated. However, MuleSoft has recently released Anypoint Code Builder, which is currently in beta and is intended to be their next generation IDE that covers the whole development process. It is based on VS Code, and there are also plans for a desktop version using VS Code extensions.
Data formats
MuleSoft is payload-agnostic and supports various data formats such as JSON, XML, and many others.
All the steps in the Mule Palette can handle the different data formats natively without having to switch from one data format to another in order to use certain steps. For example, the Write step can be directly configured to generate a file output in CSV format based on an input JSON payload without a prior transformation step.
In constrast, while Apache Camel (as the underlying framework) is also payload-agnostic, there are many steps in SAP Cloud Integration that still rely heavily on an XML payload for processing. Some examples include routing based on XPath conditions, splitting based on XPath expressions, and conversions between JSON/CSV and XML. As such, there is an overhead incurred when handling non-XML payloads due to the additional conversions needed to and from XML.
DataWeave
DataWeave is without doubt one of the key feature and strength of the Anypoint Platform. At first glance, it can be daunting to learn a new programming language, especially one that is so specific and limited to a particular vendor/platform. However, once you get past the learning curve, there is a realisation of the power and potential of the language. On one hand in its simplest form, it is used as the expression language for the Mule runtime engine, with many palette steps having fields that can be dynamically configured using DataWeave expressions. On the other hand, it is a functional language that can be used to craft powerful and complex data transformations. The benefits of having the same language for both expression and data transformation eliminates the need to switch context between one language to another.
By comparison, SAP Cloud Integration uses Camel Simple Expression Language for configuring dynamic expressions in the integration flow steps, while more complex transformations require scripting in either Groovy or JavaScript. While it is possible to use Camel’s Simple in Groovy scripts, there is still a need to be familiar with the syntax and usage of both languages.
Following are some examples of DataWeave use cases:
Multiple actions in one line of code
Dataweave allows chaining of functions, therefore creating very concise code. The following line of code flattens a hierarchical payload and remove all duplicates from the output. Additionally, the same code would work for different data formats used for the input. To achieve something similar in SAP Cloud Integration would require XSLT (only for XML input) or Groovy/Javascript and a lot more lines of code.
flatten(payload.payload) distinctBy $Transformation from one structure to another
The following shows transformation from one message structure to another. The input could be in any data format, with the resultant output generated in JSON. Additionally, filtering and sorting are included in the transformation.
%dw 2.0
output application/json
var filtered = payload filter ($.active == true and $.name != null) orderBy $.name
---
filtered map ( payload01 , indexOfPayload01 ) -> {
customerName: payload01.name default "",
accType: payload01.accountType default "",
}Live Preview
One of the handy features when working with DataWeave is the Live Preview (also called AutoPreview) of the output. This enables developers to automatically see the result of changes to the DataWeave code as it is being written. This capability is built in to Anypoint Studio, and also available as an extension for VS Code. Following is an example of Live Preview at work.
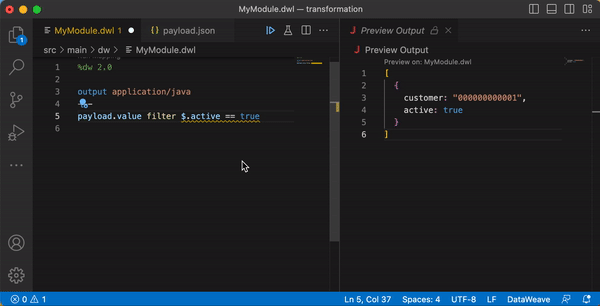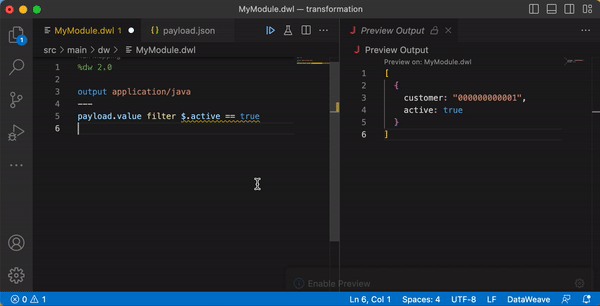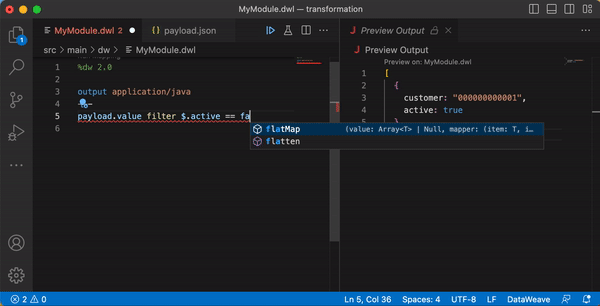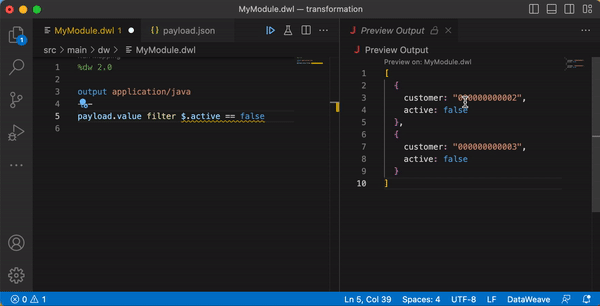
Error handling
MuleSoft adopts an error handling mechanism that is common in many programming languages. When an error is caught, it is possible to propagate the error to the parent flow, or return to the parent flow and continue with the next step there. Additionally, it is also possible to define error handler within Try scopes, or even at a Global level to catch errors that are not caught anywhere else. MuleSoft also provides the option to define custom error types, and map standard errors to them.
All of these allow complex error handling mechanism to be crafted in an elegant way without feeling too clunky.
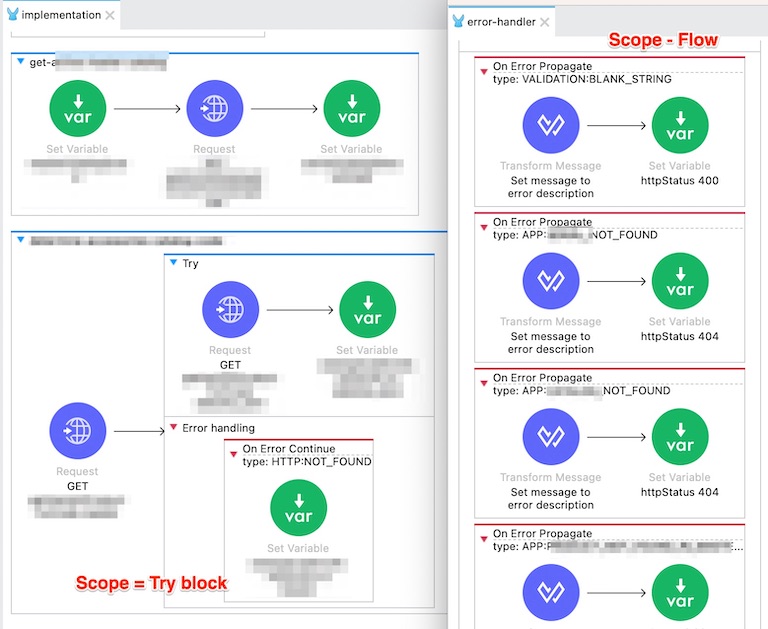
On the other hand, error handling features in SAP Cloud Integration feels limited. At the time of writing, once an exception is caught (in an exception subprocess) it is not possible to propagate it to higher levels (and handle it there). As it is also not possible to catch exceptions occurring in local integration processes in the main integration process, exception subprocesses need to be duplicated everywhere they are needed. This leads to designing workarounds (that can sometimes cumbersome) and/or adding more steps in the integration flow.
Flexible usage of source & target fields
As I mentioned at the beginning, cloud native integrations are becoming more complex where multiple HTTP/API calls are involved, together with orchestration and data enrichment. To tackle such scenarios in SAP Cloud Integration, it is quite common that the main payload body is saved in an Exchange property prior to making a subsequent HTTP/API call. After the call, data is retrieved from the payload body (response of new call) and Exchange property (payload before call) and used in further processing.
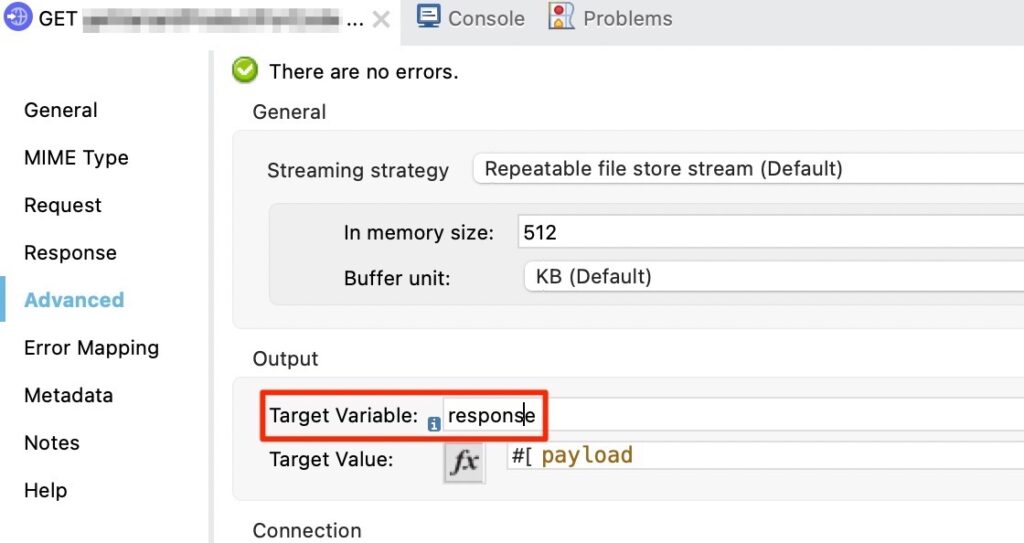
In MuleSoft, there is an option to direct the response of an HTTP call to a variable instead of replacing the main payload body. Variables in MuleSoft are similar to Exchange properties and can be used as additional data storage during execution of a Mule message. Therefore, additional steps to store and retrieve payloads are not necessary. The image below shows an example of the response of the HTTP call configured to be stored in a variable named response. It can then be accessed using DataWeave expression vars.response.
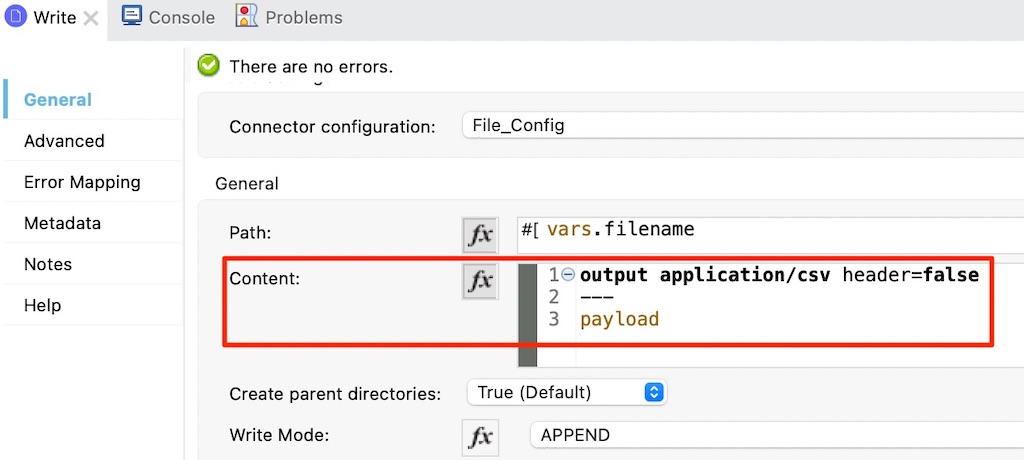
Besides that, when sending output data on channels, it is not mandatory to use the content from the main payload body. Most steps provide the capability to use a DataWeave expression to dynamically determine the content that is used for that step. Additionally, the output of the DataWeave expression is only applicable for that step and does not replace the payload body that will be passed to the next step. Such flexibility is useful when it is required to send a different content (from the main payload) in the middle of the flow but still retain the main payload for subsequent steps. The following image depicts a Write step that generates an output file in CSV format, this step does not replace the existing JSON payload that will be used in subsequent steps.
Logging
Robust logging capability is a must in any enterprise grade solution. In this area, MuleSoft utilises Apache Log4j 2 for logging. It provides a palette step named Logger – which can essentially log almost anything! From simple hardcoded text to complex DataWeave expressions, a Logger step can be added anywhere in the flow to provide better insight into the execution of the flow during runtime.
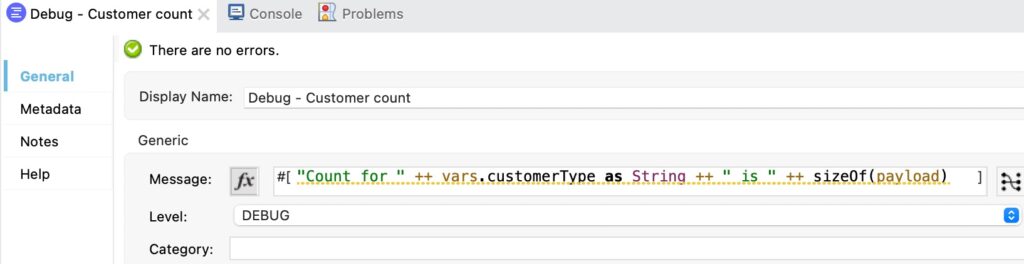
Sometimes, more intensive logging is needed for debugging of a flow that is not required during normal execution. This can be accomplished by setting the log level of the Logger step (e.g. to DEBUG), which is a common approach used in Java developments. From Anypoint Runtime Manager, the log level used during runtime execution can be adjusted accordingly. Once adjusted, subsequent executions will generate the logs corresponding to the log level.
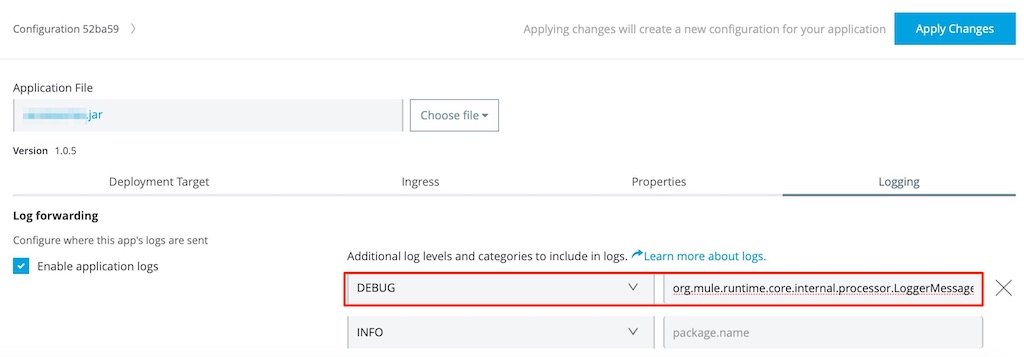
The logs generated during runtime can be viewed in Anypoint Runtime Manager. It includes search functionality which is really useful to “hunt” down certain log entries.
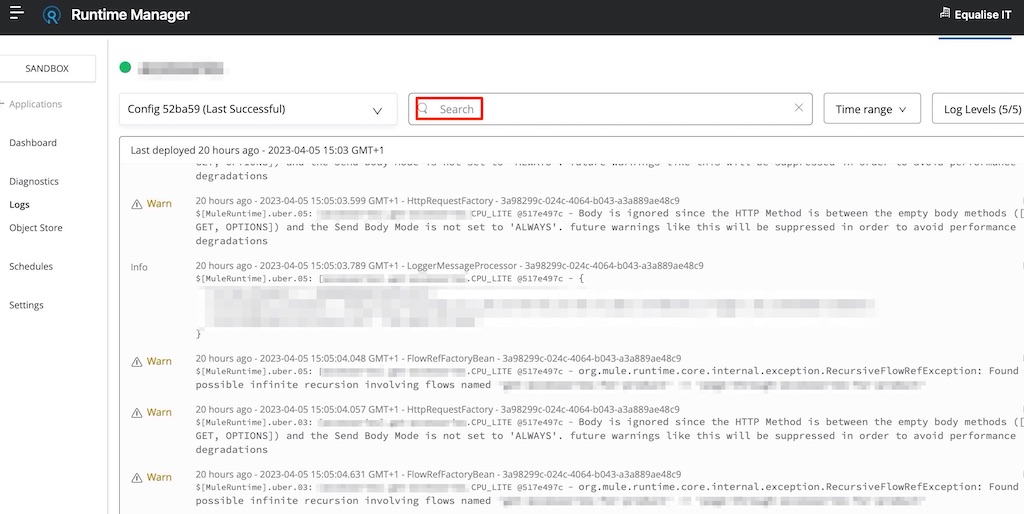
In contrast, SAP Cloud Integration does not provide a logging framework that is accessible to developers for design and debugging purposes. Most logging involves saving content into an MPL attachment – an approach which is significantly limited compared to utilising a logging framework like Log4j 2.
API policy
Once the API specification and implementation are completed, provisioning it to consuming clients and applications is pretty straightforward.
Adding API policies is achieved by just selecting the checkbox for the desired policy, unlike SAP API Management which requires dealing with pre/post-flows and configuring policies with XML snippets. The following images display implementing a policy for rate limiting with multiple SLA tiers, done with an easy-to-use UI.
Subsequently, developers of consuming applications can easily request access from Anypoint Exchange, by selecting the appropriate tier and then using the generated client ID and client secret when making calls to the API.
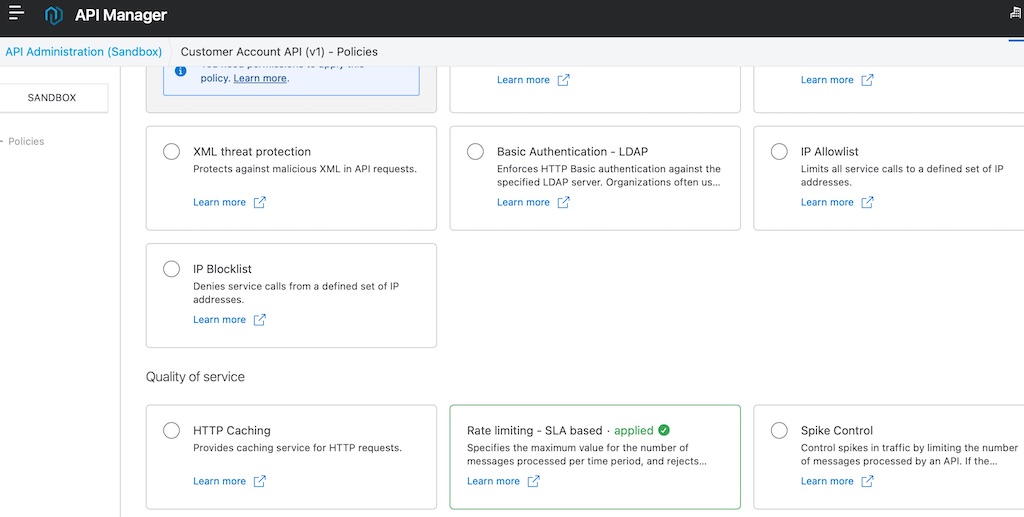
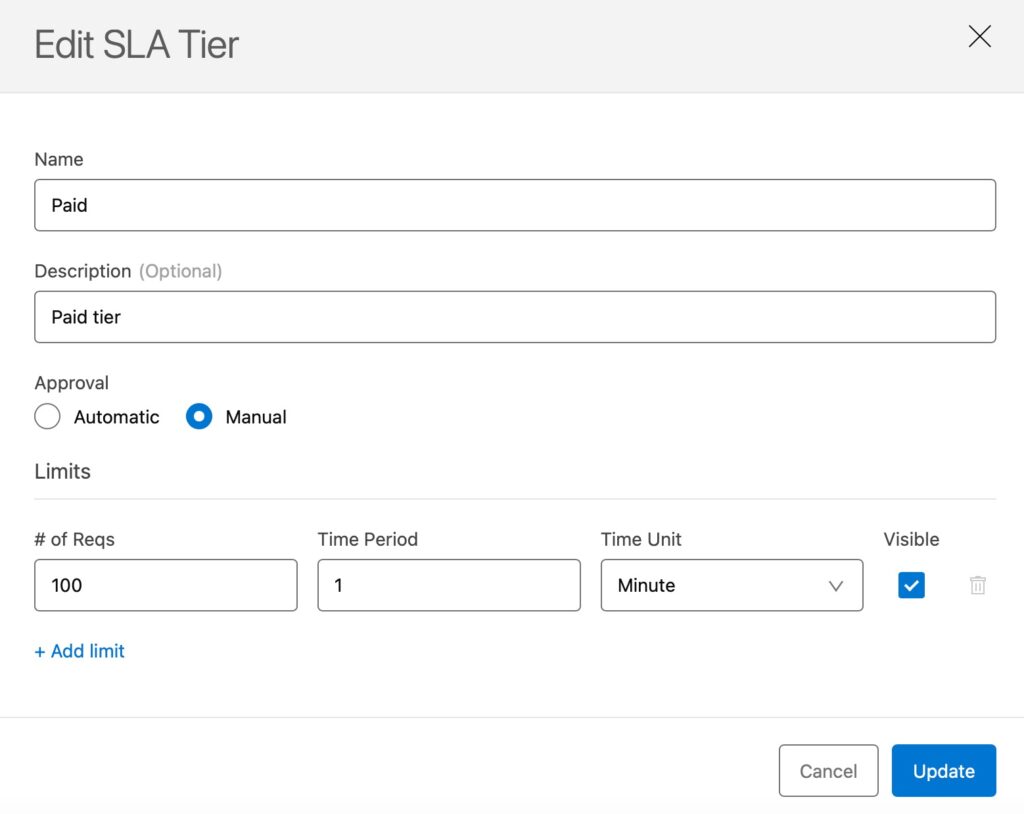
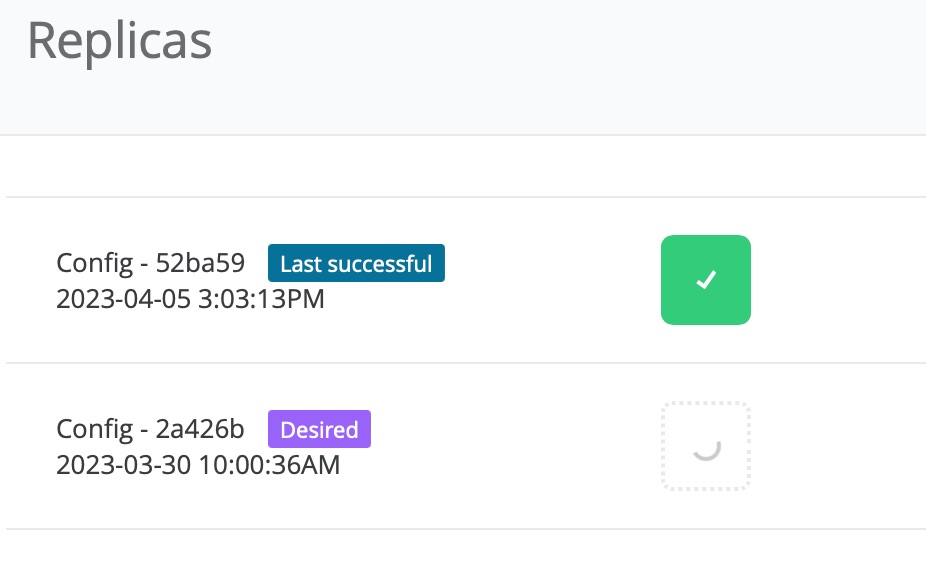
Rolling update
When deploying the API and integrations to CloudHub, rolling updates are supported out-of-the-box. CloudHub is a Kubernetes-based containerised integration platform, where each API/integration run in its own separate container. Using Kubernetes technology, each instance is deployed as a replica, and when an update is deployed, a separate replica is created and will only replace the existing replica if it is successfully deployed. This way, there is no down time when a new update is deployed.
In contrast, integration flows on SAP Cloud Integration are temporarily unavailable when a new update is deployed. Even in the case of applications developed on SAP BTP (Cloud Foundry), they require additional set up to enable blue-green deployment.
Conclusion
It was a very interesting experience migrating and reimplementing the integration flow from SAP Cloud Integration to MuleSoft Anypoint Platform. The capabilities and features provided by MuleSoft Anypoint Platform was more than able to cover the requirements of the integration without losing any existing functionality.
As a matter of fact, there were improvements and simplifications in certain areas like automatic validation by APIkit, concise codes for transformation utilising DataWeave, and a more elegant error handling mechanism. On top of that, there were extra benefits gained in the area of logging (providing more insight into runtime executions) and rolling updates (ensuring an always available service during updates).
All in all, I thoroughly enjoyed working on this development. From a capability point of view, MuleSoft Anypoint Platform is definitely a solid platform for designing and running enterprise grade integrations. From a developer point of view, it provides great tools and features in an intuitive manner, which makes it easy to get the job done.
Comments
Feel free to provide your comment, feedback and/or opinion here.
